
Generating Synthetic Data in Snowflake
Developers need realistic data to build and test effectively, but moving PII/PHI into dev environments is a massive compliance risk

Let’s dive into an example use case where synthetic data in a dev environment enables developers to interact with realistic data without exposing this group to sensitive or identifiable data.
Why synthetic data?
Testing & QA – Populate dev environments without exposing production data.
ML/AI pipelines – Build realistic training sets when real data is scarce or restricted.
Privacy compliance – Produce mock datasets that preserve statistical properties while removing PII.
Development - Enable the ability to leverage developers or systems that shouldn’t have access to PHI and PII.
Snowflake’s native SQL and built‑in functions make synthetic data generation fast, scalable, and fully managed.
Reference
Requirements
Snowflake Enterprise Edition (Required for the
GENERATE_SYNTHETIC_DATAstored procedure).
Demo Overview
We will replicate the most likely case where a company has real data in production and wants synthetic data in dev.
For this demo, we will use a gym membership table sourced from Kaggle.
describe table data_ops.public.gym_membership;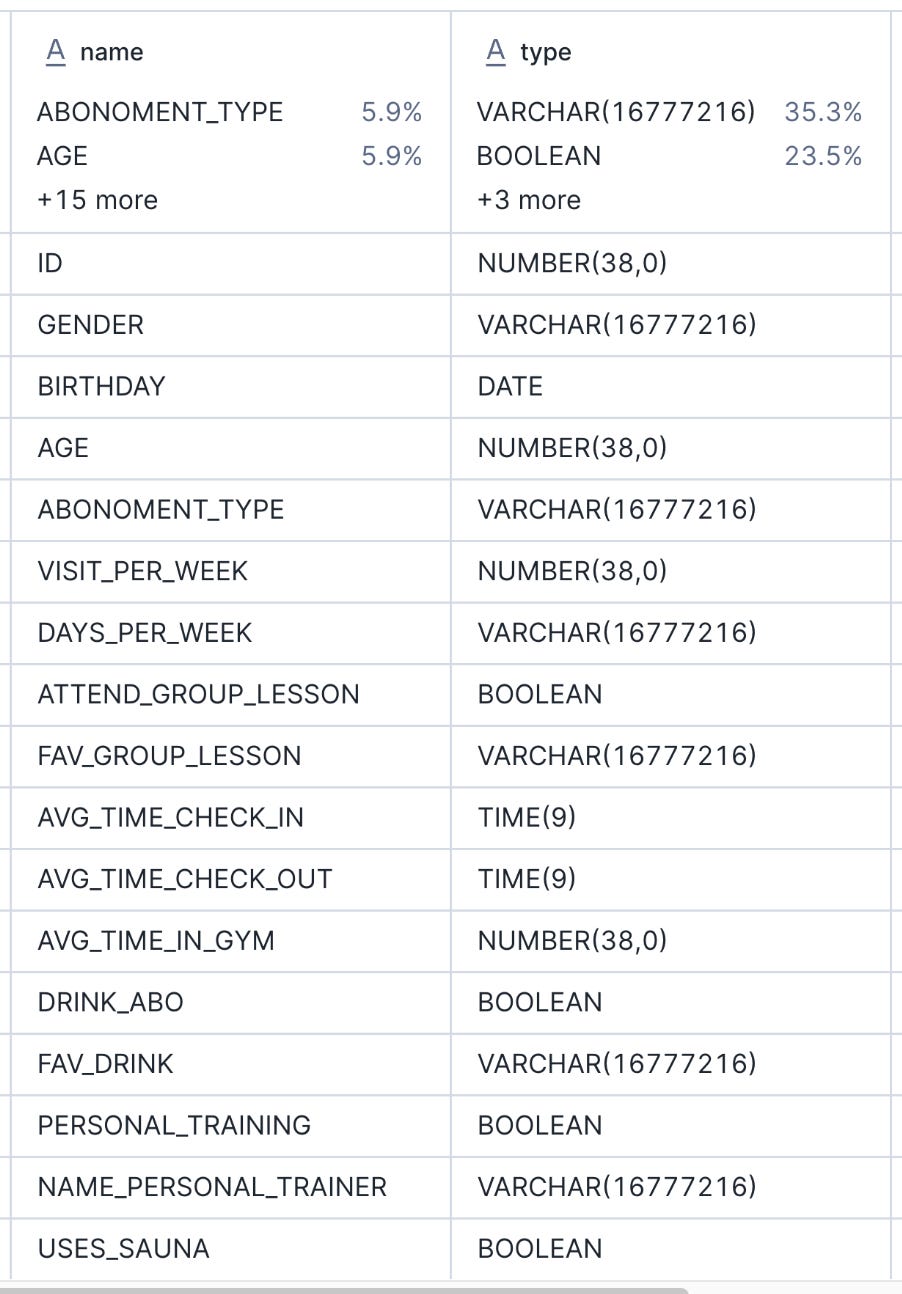
SELECT * FROM data_ops.public.gym_membership ORDER BY id LIMIT 9;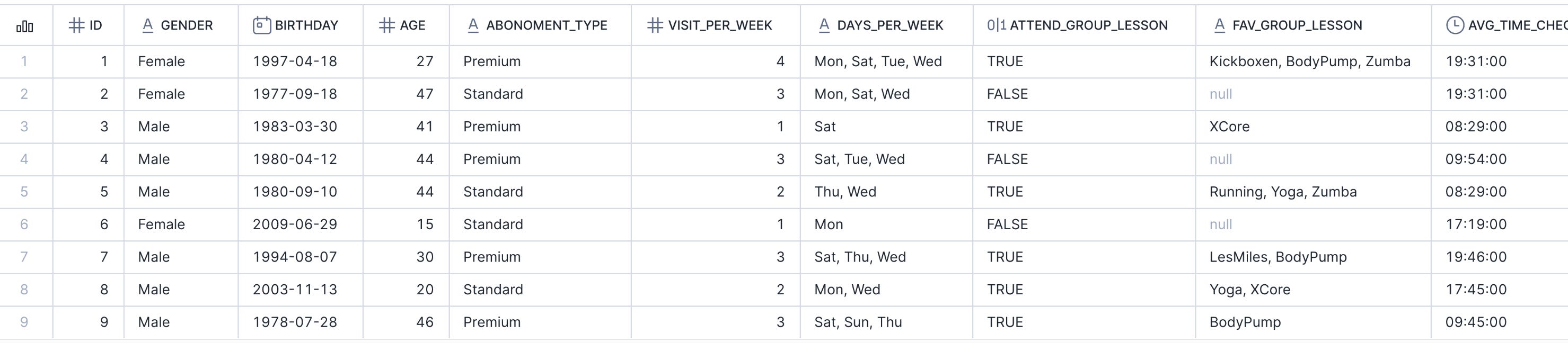
1️⃣ Environment Setup
-- Create dev & prod schemas (if they don’t already exist)
CREATE SCHEMA IF NOT EXISTS data_ops.client_dev;
CREATE SCHEMA IF NOT EXISTS data_ops.client_prod;
-- Session‑level secret used for deterministic join keys
CREATE OR REPLACE SECRET synthetic_data_secret
TYPE = SYMMETRIC_KEY
ALGORITHM = ‘GENERIC’
;2️⃣ Build the Relational Model (Prod)
Lets create a relational model by splitting the gym_membership table up into a tbl_persons table and a tbl_gym_activity table.
-- Person table – adding additional sensitive columns as part of demo
CREATE TABLE IF NOT EXISTS data_ops.client_prod.tbl_person AS
SELECT
id
, randstr(5, random()) first_name -- future synthetic first name
, randstr(5, random()) last_name -- future synthetic last name
, gender
, birthday
, age
FROM
data_ops.public.gym_membership
;
-- Gym activity table – keep business‑logic columns
CREATE TABLE IF NOT EXISTS data_ops.client_prod.tbl_gym_activity AS
SELECT
id
, abonoment_type
, visit_per_week
, days_per_week
, attend_group_lesson
, fav_group_lesson
, avg_time_check_in
, avg_time_check_out
, avg_time_in_gym
, drink_abo
, fav_drink
, personal_training
, name_personal_trainer
, uses_sauna
FROM
data_ops.public.gym_membership
;
3️⃣ Verify the Relational Model (Prod)
-- Expect identical resultset + 2 new columns first and last name.
SELECT
a.*, b.* EXCLUDE (id)
FROM
data_ops.client_prod.tbl_person a
JOIN
data_ops.client_prod.tbl_gym_activity b USING(id)
ORDER BY a.id LIMIT 9
;
4️⃣ Generate Synthetic Data (Dev)
CALL SNOWFLAKE.DATA_PRIVACY.GENERATE_SYNTHETIC_DATA({
‘datasets’:[
{
‘input_table’: ‘data_ops.client_prod.tbl_person’,
‘output_table’: ‘data_ops.client_dev.tbl_person’,
‘columns’: {
‘id’: {’join_key’: TRUE},
-- synthetic data generated for these
‘first_name’: { ‘categorical’: FALSE, ‘replace’: ‘first_name’ },
‘last_name’: { ‘categorical’: FALSE, ‘replace’: ‘last_name’ }
}
},
{
‘input_table’: ‘data_ops.client_prod.tbl_gym_activity’,
‘output_table’: ‘data_ops.client_dev.tbl_gym_activity’,
‘columns’: {
‘id’: {’join_key’: TRUE},
-- redacted data for this
‘days_per_week’: { ‘categorical’: FALSE }
}
}
],
‘similarity_filter’: TRUE,
‘consistency_secret’: SYSTEM$REFERENCE(’SECRET’, ‘synthetic_data_secret’, ‘SESSION’, ‘READ’)::STRING,
‘replace_output_tables’: TRUE
});5️⃣ Validate the Synthetic Dev Tables
Pointing the previous validation snipped to Dev now, we see every value has been properly changed, by type. Additionally, one item has been redacted.
SELECT
a.*, b.* EXCLUDE (id)
FROM
data_ops.client_dev.tbl_person a
JOIN
data_ops.client_dev.tbl_gym_activity b USING(id)
ORDER BY a.id LIMIT 9
;
6️⃣ Cleanup
-- Optional; synthetic_data_secret is session scoped.
DROP SECRET synthetic_data_secret;
DROP SCHEMA IF EXISTS data_ops.client_dev;
DROP SCHEMA IF EXISTS data_ops.client_prod;🚧 Limitations
Tables must have a minimum 20 distinct rows per table
There is an upper limit of 100 columns per table
There is a record limit of 14 million records per table
Limitations on
replacevalue types. Snowflake’s built-in types of data can replace are restricted to the listed below. Should you have a different type of data you would like to generate, you would need alternative means.uuid
name
first_name
last_name
address
full_address
email
phone
ssn
Note relations between values, i.e. birthday and age are not worked out.
🚧 Overcoming Req Limitations
Minimum 20 distinct rows per table
Duplicate data as many times as needed to top 20 records
Add hash column(s) to make set unique
Call stored procedure on table-set to generate synthetic data
Remove hash column
Remove duplicates via
group byclause
Maximum 100 columns per table
One wide table to multiple tables
Use views to vertically-split wide tables into multiple thinner tables
Preserve key across all tables
Limit the number of columns to < 100 for all sub-tables
Call synthetic data sp once for all these tables together
Once each table has been run thru sp, re-create original table
Maximum 14 million records per table
One large table to multiple smaller tables
Divide all records into as many tables as needed to accommodate set.
Run thru stored procedure
Union all tables back into one set
Other Limitations
Most of the remaining limitations can be addressed using lookup tables.
📈 Next Steps / Service Offer
If your organization needs a custom synthetic‑data pipeline—handling larger schemas, bespoke data types, or automated CI/CD integration—our team can:
Design a scalable Snowflake‑based generator using Snowpark.
Build reusable stored procedures with parameterized secret handling.
Provide ongoing support for compliance audits and data‑masking policies.
Thanks for reading! Subscribe for free to receive new posts and support my work.